
Java Records: A Closer Look
In the previous article we introduced Records, a new preview feature in Java 14. Records are providing a nice compact syntax to declare classes that are supposed to be dumb data holders. In this article, we’re going to see how Records are looking like under the hood. So buckle up!
Class Representation
Let’s start with a very simple example:
public record Range(int min, int max) {}How about compiling this code using javac:
javac --enable-preview -source 14 Range.javaThen, It’s possible to take a peek at the generated bytecode using javap:
javap RangeThis will print the following:
Compiled from "Range.java"
public final class Range extends java.lang.Record {
public Range(int, int);
public java.lang.String toString();
public final int hashCode();
public final boolean equals(java.lang.Object);
public int min();
public int max();
}Interestingly, similar to Enums, Records are normal Java classes with a few fundamental properties:
- They are declared as
finalclasses, so we can’t inherit from them. - They’re already inheriting from another class named
java.lang.Record. Therefore, Records can’t extend any other class, as Java does not allow multiple-inheritance. - Records can implement other interfaces.
- For each component, there is an accessor method, e.g.
maxandmin. - There are auto-generated implementations for
toString,equalsandhashCodebased on all components. - Finally, there is an auto-generated constructor that accepts all components as its arguments.
Also, the java.lang.Record is just an abstract class with a protected no-arg constructor and a few other basic abstract methods:
public abstract class Record {
protected Record() {}
@Override
public abstract boolean equals(Object obj);
@Override
public abstract int hashCode();
@Override
public abstract String toString();
}Nothing special is about this class!
The Curious Case of Data Classes
Coming from a Kotlin or Scala background, one may spot some similarities between Records in Java, Data Classes in Kotlin and Case Classes in Scala. On the surface, they all share one very fundamental goal: To facilitate writing data holders.
Despite this fundamental similarity, things are very different at the bytecode level.
Kotlin’s Data Class
For the sake of comparison, let’s see a Kotlin data class equivalent of Range:
data class Range(val min: Int, val max: Int)Similar to Records, Kotlin compiler generates accessor methods, default toString, equals and hashCode implementations and a few more functions based on this simple one-liner.
Let’s see how the Kotlin compiler generates the code for, say, toString:
Compiled from "Range.kt"
public java.lang.String toString();
descriptor: ()Ljava/lang/String;
flags: (0x0001) ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: new #36 // class StringBuilder
3: dup
4: invokespecial #37 // Method StringBuilder."<init>":()V
7: ldc #39 // String Range(min=
9: invokevirtual #43 // Method StringBuilder.append:(LString;)LStringBuilder;
12: aload_0
13: getfield #10 // Field min:I
16: invokevirtual #46 // Method StringBuilder.append:(I)LStringBuilder;
19: ldc #48 // String , max=
21: invokevirtual #43 // Method StringBuilder.append:(LString;)LStringBuilder;
24: aload_0
25: getfield #16 // Field max:I
28: invokevirtual #46 // Method StringBuilder.append:(I)LStringBuilder;
31: ldc #50 // String )
33: invokevirtual #43 // Method StringBuilder.append:(LString;)LStringBuilder;
36: invokevirtual #52 // Method StringBuilder.toString:()LString;
39: areturnWe issued the javap -c -v Range to generate this output. Also, here we’re using the simple class names for the sake of brevity.
Anyway, Kotlin is using the StringBuilder to generate the string representation instead of multiple string concatenations (Like any decent Java developer!). That is:
- At first, it creates a new instance of
StringBuilder(index 0, 3, 4). - Then it appends the literal
Range(min=string (index 7, 9). - Then it appends the actual min value (index 12, 13, 16).
- Then it appends the literal
, max=(index 19, 21). - Then it appends the actual max value (index 24, 25, 28).
- Then it closes the parentheses by appending the
)literal (index 31, 33). - Finally, it builds the
StringBuilderinstance and returns it (index 36, 39).
Basically, the more we have properties in our data class, the lengthier the bytecode and consequently longer startup time.
Scala’s Case Class
Let’s write the case class equivalent in Scala:
case class Range(min: Int, max: Int)At first glance, Scala seems to generate a much simpler toString implementation:
Compiled from "Range.scala"
public java.lang.String toString();
descriptor: ()Ljava/lang/String;
flags: (0x0001) ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #89 // Field ScalaRunTime$.MODULE$:LScalaRunTime$;
3: aload_0
4: invokevirtual #111 // Method ScalaRunTime$._toString:(LProduct;)LString;
7: areturnHowever, the toString calls the scala.runtime.ScalaRunTime._toString static method. That, in turn, calls the productIterator method to iterate through this Product Type. This iterator calls the productElement method which looks like:
public java.lang.Object productElement(int);
descriptor: (I)Ljava/lang/Object;
flags: (0x0001) ACC_PUBLIC
Code:
stack=3, locals=3, args_size=2
0: iload_1
1: istore_2
2: iload_2
3: tableswitch { // 0 to 1
0: 24
1: 34
default: 44
}
24: aload_0
25: invokevirtual #55 // Method min:()I
28: invokestatic #71 // Method BoxesRunTime.boxToInteger:(I)LInteger;
31: goto 59
34: aload_0
35: invokevirtual #58 // Method max:()I
38: invokestatic #71 // Method BoxesRunTime.boxToInteger:(I)LInteger;
41: goto 59
44: new #73 // class IndexOutOfBoundsException
47: dup
48: iload_1
49: invokestatic #71 // Method BoxesRunTime.boxToInteger:(I)LInteger;
52: invokevirtual #76 // Method Object.toString:()LString;
55: invokespecial #79 // Method IndexOutOfBoundsException."<init>":(LString;)V
58: athrow
59: areturnThis basically switches over all properties of the case class. For instance, if the productIterator wants the first property, it returns the min. Also, when the productIterator wants the second element, it will return the max value. Otherwise, it will throw an instance of IndexOutOfBoundsException to signal an out of bound request.
Again, the more we have properties in a case class, we would have more of those switch arms. Therefore, the bytecode length is proportional to the number of properties. Hence, the same problem as Kotlin’s data class.
Invoke Dynamic
Let’s take an even closer look to the bytecode generated for the Java Records:
Compiled from "Range.java"
public java.lang.String toString();
descriptor: ()Ljava/lang/String;
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokedynamic #18, 0 // InvokeDynamic #0:toString:(LRange;)Ljava/lang/String;
6: areturnRegardless of the number of record components, this will be the bytecode. A simple, polished and elegant solution. But how this invokedynamic thing works?
Introducing Indy
Invoke Dynamic (Also known as Indy) was part of JSR 292 intending to enhance the JVM support for Dynamic Type Languages. After its first release in Java 7, The invokedynamic opcode along with its java.lang.invoke luggage is used quite extensively by dynamic JVM-based languages like JRuby.
Although indy specifically designed to enhance the dynamic language support, it offers much more than that. As a matter of fact, it’s suitable to use wherever a language designer needs any form of dynamicity, from dynamic type acrobatics to dynamic strategies! For instance, the Java 8 Lambda Expressions are actually implemented using invokedynamic, even though Java is a statically typed language!
User-Definable Bytecode
For quite some time JVM did support four method invocation types: invokestatic to call static methods, invokeinterface to call interface methods, invokespecial to call constructors, super() or private methods and invokevirtual to call instance methods.
Despite their differences, these invocation types share one common trait: we can’t enrich them with our own logic. On the contrary, invokedynamic enables us to Bootstrap the invocation process in any way we want. Then the JVM takes care of calling the Bootstrapped Method directly.
How Does Indy Work?
The first time JVM sees an invokedynamic instruction, it calls a special static method called Bootstrap Method. The bootstrap method is a piece of Java code that we’ve written to prepare the actual to-be-invoked logic:
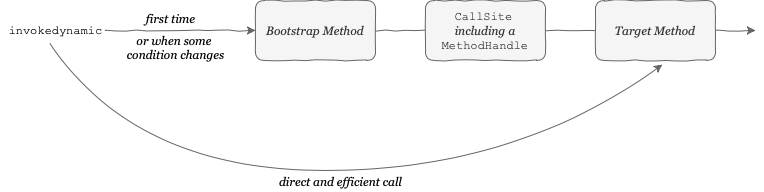
Then the bootstrap method returns an instance of java.lang.invoke.CallSite. This CallSite holds a reference to the actual method, i.e. MethodHandle. From now on, every time JVM sees this invokedynamic instruction again, it skips the Slow Path and directly calls the underlying executable. The JVM continues to skip the slow path unless something changes.
Why Indy?
As opposed to the Reflection APIs, the java.lang.invoke API is quite efficient since the JVM can completely see through all invocations. Therefore, JVM may apply all sorts of optimizations as long as we avoid the slow path as much as possible!
In addition to the efficiency argument, the invokedynamic approach is more reliable and less brittle because of its simplicity.
Moreover, the generated bytecode for Java Records is independent of the number of properties. So, less bytecode and faster startup time.
Finally, let’s suppose a new version of Java includes a new and more efficient bootstrap method implementation. With invokedynamic, our app can take advantage of this improvement without recompilation. This way we have some sort of Forward Binary Compatibility. Also, That’s the dynamic strategy we were talking!
The Object Methods
Now that we are familiar enough with Indy, let’s make sense of the invokedynamic in Records bytecode:
invokedynamic #18, 0 // InvokeDynamic #0:toString:(LRange;)Ljava/lang/String;Look what I found in the Bootstrap Method Table:
BootstrapMethods:
0: #41 REF_invokeStatic java/lang/runtime/ObjectMethods.bootstrap:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/TypeDescriptor;Ljava/lang/Class;Ljava/lang/String;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/Object;
Method arguments:
#8 Range
#48 min;max
#50 REF_getField Range.min:I
#51 REF_getField Range.max:ISo the bootstrap method for Records is called bootstrap which resides in the java.lang.runtime.ObjectMethods class. As you can see, this bootstrap method expects the following parameters:
- An instance of
MethodHandles.Lookuprepresenting the lookup context (TheLjava/lang/invoke/MethodHandles$Lookuppart). - The method name (i.e.
toString,equals,hashCode, etc.) the bootstrap is going to link. For example, when the value istoString, bootstrap will return aConstantCallSite(aCallSitethat never changes) that points to the actualtoStringimplementation for this particular Record. - The
TypeDescriptorfor the method (Ljava/lang/invoke/TypeDescriptorpart). - A type token, i.e.
Class<?>, representing the Record class type. It’sClass<Range>in this case. - A semi-colon separated list of all component names, i.e.
min;max. - One
MethodHandleper component. This way the bootstrap method can create aMethodHandlebased on the components for this particular method implementation.
The invokedynamic instruction passes all those arguments to the bootstrap method. Bootstrap method, in turn, returns an instance of ConstantCallSite. This ConstantCallSite is holding a reference to requested method implementation, e.g. toString.
Reflecting on Records
The java.lang.Class API has been retrofitted to support Records. For example, given a Class<?>, we can check whether it’s a Record or not using the new isRecord method:
jshell> var r = new Range(0, 42)
r ==> Range[min=0, max=42]
jshell> r.getClass().isRecord()
$5 ==> trueIt obviously returns false for non-record types:
jshell> "Not a record".getClass().isRecord()
$6 ==> falseThere is, also, a getRecordComponents method which returns an array of RecordComponent in the same order they defined in the original record. Each java.lang.reflect.RecordComponent is representing a record component or variable of the current record type. For example, the RecordComponent.getName returns the component name:
jshell> public record User(long id, String username, String fullName) {}
| created record User
jshell> var me = new User(1L, "alidg", "Ali Dehghani")
me ==> User[id=1, username=alidg, fullName=Ali Dehghani]
jshell> Stream.of(me.getClass().getRecordComponents()).map(RecordComponent::getName).
...> forEach(System.out::println)
id
username
fullNameIn the same way the getType method returns the type token for each component:
jshell> Stream.of(me.getClass().getRecordComponents()).map(RecordComponent::getType).
...> forEach(System.out::println)
long
class java.lang.String
class java.lang.StringIt’s even possible to get a handle to accessor methods via getAccessor:
jshell> var nameComponent = me.getClass().getRecordComponents()[2].getAccessor()
nameComponent ==> public java.lang.String User.fullName()
jshell> nameComponent.setAccessible(true)
jshell> nameComponent.invoke(me)
$21 ==> "Ali Dehghani"Annotating Records
Java permits to annotate Records, As long as the annotation is applicable to a record or its members. Additionally, there would be a new annotation ElementType called RECORD_COMPONENT. Annotations with this target can only be used on record components:
@Target(ElementType.RECORD_COMPONENT)
public @interface Param {}Serialization
Any new Java feature without a nasty relationship with Serialization would be incomplete. This time around, however, the relationship does not sound as disgusting as we’re used to.
Although Records are not by default serializable, it’s possible to make them so just by implementing the java.io.Serializable marker interface.
Serializable records are serialized and deserialized differently than ordinary serializable objects. The updated javadoc for ObjectInputStream states that:
- The serialized form of a record object is a sequence of values derived from the record components.
- The process by which record objects are serialized or externalized cannot be customized; any class-specific
writeObject,readObject,readObjectNoData,writeExternal, andreadExternalmethods defined by record classes are ignored during serialization and deserialization. - The
serialVersionUIDof a record class is0Lunless explicitly declared.
Conclusion
Java Records are going to provide a new way to encapsulate data holders. Even though currently, they’re limited in terms of functionality (Compared to what Kotlin or Scala are offering), the implementation is solid.
The first preview of Records would be available in March 2020. In this article, we’ve used the openjdk 14-ea 2020-03-17 build, since the Java 14 is yet to be released!