
On Fair & Scalable Locks
There are many things we take for granted in our everyday life. Probably Locks aren’t one of them but ain’t them adorable?
var lock = new ReentrantLock();
try {
// critical section
} finally {
lock.unlock();
}They help us to easily enforce Mutual Exclusion on a particular piece of code. Anyway, we certainly take advantage of this sort of primitives while using modern programming languages. However, one might argue that in the absence of this particular abstraction, we could easily implement a world-class one.
Let’s do this then.
Test and Set
Locks are either acquired by someone or are free. So, in our first attempt, we can use a single atomic boolean state to represent this duality:
public final class TestAndSetLock implements Lock {
private final AtomicBoolean state = new AtomicBoolean();
// omitted
}Then to acquire the lock, we need to atomically change this state to true:
public void lock() {
while (state.getAndSet(true));
}Here, we’re trying to change the state to true and return the previous value atomically. Therefore, if the returned value was already true, then somebody did beat us in this competition. Anyway, we would keep trying until the lock is acquired by us!
The unlock operation, however, is much simpler:
public void unlock() {
state.set(false);
}Test, Test, And Set
One might argue that when we already know the lock is acquired, there is no point for an attempt to test and set:
public final class TestAndTestAndSetLock implements Lock {
private final AtomicBoolean state = new AtomicBoolean();
@Override
public void lock() {
while (true) {
while (state.get());
if (!state.getAndSet(true)) return;
}
}
// omitted
}If the lock is acquired, i.e. the state is true, then we won’t even try to acquire the lock and wait until it becomes available again. As soon as the current lock holder releases it, then we would perform as many as tests to acquire the lock!
Seems like yet another premature optimization at first, so let’s benchmark these two against each other!
A Tale of Two Tests
In this simple benchmark, we’re going to spawn a few threads:
@Threads(50)
@Fork(value = 2)
@Warmup(iterations = 5)
@State(Scope.Benchmark)
public class MicroBenchmark {
private final Lock tasLock = new TestAndSetLock();
private final Lock ttasLock = new TestAndTestAndSetLock();
private Consumer<Lock> action = lock -> {
lock.lock();
try {
if (System.currentTimeMillis() == 0) {
System.out.println("Time Travel?");
}
} finally {
lock.unlock();
}
};
// omitted
}Each thread is going to run lots of iterations. In each iteration, they’re going to acquire the lock, call a very simple system call, a predictable branch and then release the lock:
@Benchmark
@BenchmarkMode(Throughput)
public void tasLock() {
action.accept(tasLock);
}
@Benchmark
@BenchmarkMode(Throughput)
public void ttasLock() {
action.accept(ttasLock);
}If we run the benchmark, we would see something like:
Benchmark Mode Cnt Score Error Units
MicroBenchmark.tasLock thrpt 40 2149458.491 ± 1523535.026 ops/s
MicroBenchmark.ttasLock thrpt 40 2360037.269 ± 1586001.428 ops/sApparently that seemingly premature optimization has a better throughput compared to the TAS lock. Let’s see how these two compete in terms of latency:
Benchmark Mode Cnt Score Error Units
MicroBenchmark.tasLock avgt 40 0.002 ± 0.004 s/op
MicroBenchmark.ttasLock avgt 40 0.001 ± 0.002 s/opSimilarly, the TTAS implementation outperforms the TAS one in terms of latency with less jitter.
What is the cause of this performance degradation?
Shared Multi-Processor Architecture
CPU cores are responsible for executing program instructions. Therefore, they need to retrieve both instructions and required data from RAM.
As CPUs are capable of carrying out a ridiculous number of instructions per second, this fetching from RAM model is not that ideal for them. To improve the overall performance, processors are using whole lots of tricks like Out of Order Execution, Branch Prediction, Speculative Execution, and of course Caching.
This is where the following memory hierarchy comes into play:
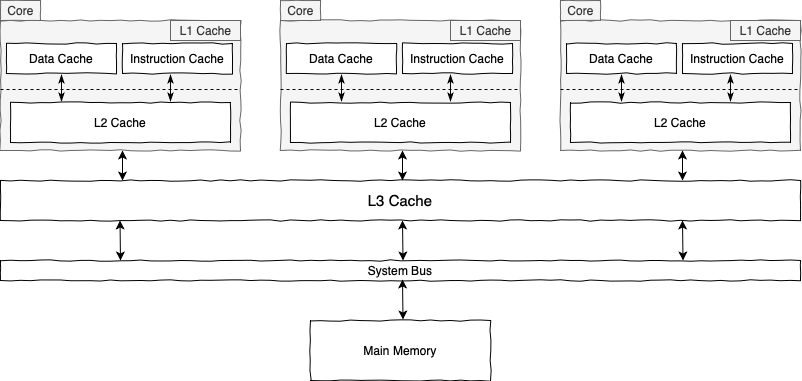
That’s a stupid depiction for a few processing units sharing one big main memory, an architecture commonly known as Shared Multi-Processor Architecture.
As different cores execute more instructions and manipulate more data, they fill up their caches with more relevant data and instructions. When a core looks for some specific data, first it tries to find it in L1, L2, and L3 caches respectively. If it couldn’t find the requested piece of data, then it tries to fetch it from the main memory.
How different processors communicate with memory and their other counterparts?
Communication
The Interconnect module controls the communication between different CPU cores and main memory. In a typical SMP architecture, the Bus is this interconnect module. The most important thing about this interconnect thing is the fact that it’s a finite shared resource.
Therefore, if one processor is using too much of this for communication, other communications may be delayed. The more processors compete for this resource, the more the delay time.
But we don’t do that, right?
Coherence Cost
As it turned out, we just did that! Let’s take another look at our first attempt to implement the lock method:
public void lock() {
while (state.getAndSet(true));
}Suppose one thread is currently holding the lock. While trying to acquire the same lock, other threads and ultimately CPU cores go through the following steps:
- Setting the
statetotrue, which in turn invalidates this cached value in other cores. - Testing the previous
statevalue and repeat the process if it was alreadytrue.
Now imagine these steps in a highly concurrent context. Lots of threads are constantly invalidating the cached state value. This, in turn, would make processors communicate with each other about the invalidation and also, consult with RAM to get the new value. Basically, we’re imposing a lot of cache misses to the processors and generating an unreasonable amount of bus traffic, our shared finite resource.
On the contrary, the TTAS implementation takes advantage of this memory hierarchy:
public void lock() {
while (true) {
while (state.get());
if (!state.getAndSet(true)) return;
}
}Once one thread acquires the lock, other contending ones will constantly read the cached value. So this simple test dramatically reduces the bus traffic when someone is holding the lock.
But what if the holder releases the lock?
Unfair Unfortunate Similarities
Let’s add the builtin Lock implementation in Java to our benchmark mix:
private final Lock reentrantLock = new ReentrantLock();
@Benchmark
@BenchmarkMode(Throughput)
public void reentrantLock() {
action.accept(reentrantLock);
}If we run the benchmark:
Benchmark Mode Cnt Score Error Units
MicroBenchmark.reentrantLock thrpt 40 14259843.631 ± 82347.669 ops/s
MicroBenchmark.tasLock thrpt 40 2149458.491 ± 1523535.026 ops/s
MicroBenchmark.ttasLock thrpt 40 2360037.269 ± 1586001.428 ops/sWow! Java’s builtin approach beats our TTAS implementation by a whopping margin! The problem with TTAS is not when everyone is trying to acquire the lock, it’s when the holder releases the lock:
public void unlock() {
state.set(false);
}When the current holder releases the lock by storing false into state, all other processors running this part of the lock method:
while (state.get());Would encounter a cache miss. Therefore, for the same reasons, the overall performance would degrade.
The main issue with Test and Set and Test, Test, and Set implementations is the fact that they share the same hotspot. Too much contention exposes that hotspot in a way that it becomes the bottleneck.
Also, there is another big problem with these implementations and it’s Fairness. That is, if P1 is currently trying to acquire the lock and then P2 comes in. When the lock gets released there is no guarantee that P1 can get in first. These approaches do not exhibit a FIFO-like characteristic.
Queue-Based Locks
To fix the memory hotspot and fairness problems associated with TAS and TTAS, we’re going to use the most underrated data structure ever: Linked List.
As this is going to be a variation of the famous CLH Lock, let’s start with a simple sentinel node:
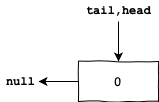
Each node in this linked list encapsulates two pieces of information:
- An integral
waitStatusvalue. Different values mean different states. For instance, one value might represent the willingness of a thread to acquire the lock. Also, we may reserve other values to represent cancellation or even waiting on a condition. For the sake of simplicity, let’s suppose1means that either the current thread is holding the lock or willing to acquire it soon. - A pointer to the previous node in the linked list.
- Additionally, we have two pointers pointing to the first and last nodes in the linked list (or queue).
Now suppose one thread comes to acquire the lock. First, we create a node for it with waitStatus value equal to 1:

Then we atomically make the tail to point to the new node and return the previous tail value. Then we use that previous value as the predecessor of the new node:
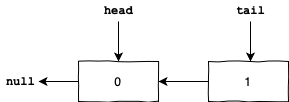
The new node can acquire the lock if and only if the waitStatus value for its predecessor is 0. Otherwise, it should spin on its predecessor waitStatus until it becomes 0.
Basically, one node can acquire the lock when all nodes in front of it in the queue have previously acquired and released the lock. Obviously, this approach exhibits a FIFO behavior and hence is fair.
Additionally, instead of spinning on one single state, each node is spinning on its predecessor waitStatus. Therefore, we alleviate the memory hotspot problem by distributing the spinning spot!
What a thread should do when it can’t acquire the lock?
Spin or Block?
So far, the blocked thread just spins on some condition until it gets a chance to acquire the lock. That is, when the lock is contended, the thread executes a few instructions and re-evaluates the lock condition again. This behavior is commonly known as Lock Spinning.
In addition to spinning, the thread can be placed in a queue and get notified when the lock is available. Which option should we choose then?
If the contended lock will be available after a short amount of time, then queuing and notifying the blocked thread would be an overkill. So we’re better off using Lock Spinning. On the other hand, if the lock would be held for a long period of time, then it’s better to wait for a notification.
These two options were some common that, before Java 7, we could control this behavior for Java’s intrinsic locks via the -XX:+UseSpinning tuning flag. Modern JVMs, however, no longer support this particular tuning.
Parking the Thread
Anyway, in order to support blocking, in addition to spinning, we should encapsulate two more things in each node:
- One pointer to the next node on the linked list. This way we can signal the successor node to wake up and acquire the lock.
- We also would need to have a reference to the
Threadthat owns the current node. ThisThreadcan be used for park and unpark operations.
Then every time a thread can’t acquire a lock, it first spins on its predecessor’s waitStatus for a short amount of time, say one microsecond. After that, the thread blocks itself and waits for a notification from one of its predecessors.
Barging & Fairness Cost
Suppose the current lock holder is about to release the lock. As few other threads are blocked in the queue and waiting for a chance, a new thread comes in to acquire the lock.
As it turns out, it’s more efficient to allow the new thread to barge in ahead of others that are blocked and queued, mainly because of the overhead associated with notifying parked threads.
Lock throughput and scalability are generally highest when we use the barging idea:
private final Lock fairLock = new ReentrantLock(true);
@Benchmark
@BenchmarkMode(Throughput)
public void fairLock() {
action.accept(fairLock);
}ReentrantLocks are not completely fair by default. However, by passing a true flag to its constructor, we can opt-in for fairness:
Benchmark Mode Cnt Score Error Units
MicroBenchmark.fairLock thrpt 40 193316.404 ± 1234.617 ops/s
MicroBenchmark.reentrantLock thrpt 40 13100539.609 ± 118438.392 ops/s
MicroBenchmark.tasLock thrpt 40 2149458.491 ± 1523535.026 ops/s
MicroBenchmark.ttasLock thrpt 40 2360037.269 ± 1586001.428 ops/sThe things we do for fairness: The ReentrantLock with barging (Also known as convoy-avoidance or even renouncement strategy) outperforms the fair one by 6600 percent. Even the simple TAS and TTAS implementations have more throughput.
So don’t pass a simple true to ReentrantLock’s constructor willy-nilly!
Introducing AbstractQueuedSynchronizer
Java 6 introduced a truly well-named abstraction called AbstractQueuedSynchronizer to facilitate implementing queue-based synchronizers. This abstraction incorporates a few, by now, familiar ideas to be a scalable synchronizer swiss army knife:
- A queue of CLH Nodes to mitigate the memory hotspot problem and support fairness.
- Switching between spinning and blocking.
- Supporting Cancellation and Conditions.
- Supporting Convoy-Avoidance strategy.
- Supporting Exclusive and Shared modes. Locks are usually using the exclusive mode, reader locks may use the shared mode and latches can use the shared modes.
This is a very generic abstraction and can be used to implement many forms of synchronizers. As a matter of fact, the ReentrantLock and CountDownLatch in Java are implemented using this abstraction.
There is, also, another abstraction called AbstractQueuedLongSynchronizer, with exactly the same structure, properties, and methods as AbstractQueuedSynchronizer with one difference: it maintains its state as a long making it useful for creating synchronizers that require 64 bits of state, e.g. barrier.
Conclusion
In this article, we did evaluate different options we may encounter along the way of implementing a Lock or Mutex. This is, of course, just an introduction to this subject and there are a lot more cases and ideas to cover. Let’s hope this serves us as a good starting point!
In January 1990, Thomas A. Anderson published a paper on The performance of Spin Lock Alternatives for shared-memory multiprocessors. In the paper, Anderson evaluated efficient algorithms for software spin-waiting given the hardware support for atomic instructions.
Also, looking at the source code, e.g. Java or Golang or libraries like PThreads, can give us a good idea of how those concepts are actually implemented.
As always, the source codes are available at GitHub!